
This is a guest blog by Jonathan Cheshire who is an independent contributor. They are in their final year as Computer Science (BSc) student, and occasional freelance Software Engineer.
I was recently tasked with rebuilding the backend system for AirDeveloppa's AQI web app (in Rust) before implementing some extra features required for the product to move to its next stage. When it was time to implement user authentication, I chose to use Pangea's AuthN service to save time, allowing me to focus on the app's core features and business logic without reinventing the wheel.
AirDeveloppa
Based in Chiang Mai, AirDeveloppa has already established itself as a manufacturer of low-cost and highly effective air purification devices. If you've spent any amount of time in Chiang Mai during its smoky season then you'll understand how important this is for the local residents and expats who live there. Providing air purifiers for people to use in their own homes is a valuable service, but it doesn't solve an important issue: If you want to go out, either for a meal or to find a place to work remotely, how can you make sure you go somewhere with decent air quality?
AirDeveloppa offers a solution to this problem with their new app, which helps customers find local businesses with good air quality
AQI Aggregation
The way the AirDeveloppa app collects AQI (Air Quality Index) readings from businesses is straightforward:
Each business has an AirCheck device that monitors the indoor AQI and sends readings at regular intervals to the backend API.
The backend verifies that the readings have been sent from a verified AirCheck device, using a secret key stored on the device itself.
Readings are stored in a database and associated with the business that the device has been registered to. This data can then be queried with geographic coordinates, allowing the app to display any AQI readings within a specific area on the map. They're also aggregated into average readings for the past hour and the past 24 hours.
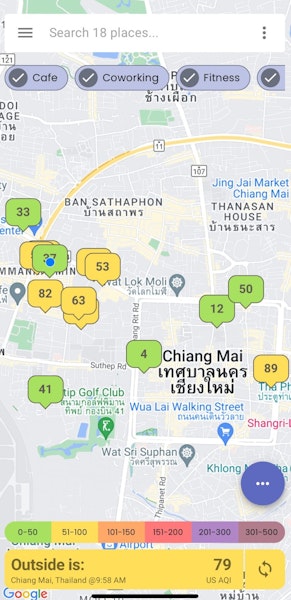
There is, however, one obvious issue that needs to be addressed: how can users know that the AQI readings are representative of the business's actual indoor AQI? Even if we've verified that the devices themselves are genuine and only send valid AQI readings, there are many ways to cheat the system. For example, a business owner could put the AirCheck device in a small locked cupboard that is never exposed to air from outside, or they could even put it in a completely different location (maybe their own house) that they know will always have favourable AQI readings.
This is where the verification system comes in.
Verification
Users of the app are incentivized, via micropayments, to verify AQI readings by "checking in" to the business and confirming that the AirCheck device is in a reasonable location.
This also has the added benefit of attracting potential customers to the business itself.
Customers simply provide their ZBD wallet address to receive their reward payment, so why do we need an authentication system if users aren’t required to sign in? Well, the business owners need to be able to sign in to a dashboard in order to top-up their credit, manage the amount paid per check-in, and to set daily budgets limiting the amount of rewards paid out in a single day. This is where I used Pangea's AuthN service.
Pangea's AuthN Service
Before I talk about how I used it, I think it's important to talk about why I used it.
There are plenty of pros and cons to consider when deciding between using a 3rd party auth provider and building your own auth system from scratch (or using one of your framework's built-in auth systems, e.g. Laravel and Breeze) but this blog post isn't intended to be a comprehensive guide, so I'll simply list the reasons I used one for this particular project:
1. Liability: If you're storing usernames and passwords in your database, then it's your responsibility to ensure the data is protected. For large corporations this isn't such a big issue, but when I'm implementing systems for small start-ups, I prefer to reduce the amount of personal liability they have to take on.
2. Speed: In this situation, I had to build a system with a lot of moving parts in a fairly limited amount of time. I needed to be able to move fast without compromising on security/reliability, and a decent 3rd party service like AuthN is perfect for this.
3. Simplicity: The rest of the system is complex enough, so removing complexity in any other areas leaves me with more room to focus on the core business logic of the application.
Now, why Pangea specifically? I'd already used other Pangea services before this project, so I know how easy their APIs are in general and that was definitely a contributing factor. But for me the most important thing is that Pangea is a security-oriented company. If I'm trusting a 3rd party with sensitive customer information, I'm going to choose the one that has the best reputation for security, one that values it above all else. Data breaches are far too common these days, so I want to be confident that user information is secure.
The ease-of-use for Pangea's APIs also makes all their services essentially language agnostic. If, like me, you're using a language such as Rust which isn't widely supported by 3rd party auth providers, it's important to have an API that's easy to use so you can quickly write a type-safe wrapper with proper error handling.
Implementation
I should probably briefly touch on why I decided to rewrite the entire Node.js backend in Rust before implementing the extra functionality for user check-ins and the business dashboard. The first thing I did when I took this job on was to familiarize myself with the code for the existing system. It was bad.
After running some load tests, I found out that it wasn't capable of handling even 2 or 3 concurrent requests without causing the entire backend system to hang (which required a manual restart on AWS every time). I'm not an expert with Node.js but I think this had something to do with the previous developer not properly using async code, essentially making every request a blocking operation. On top of this, there were just a lot of other issues with how the code had been written, making it difficult to build on top of without random things breaking for obscure reasons.
So, I knew it needed to either be re-written from scratch or refactored to the point where it's basically a re-write with extra steps. I chose Rust for a few simple reasons:
1. Familiarity: It's the language I'm most familiar with, especially when it comes to writing backend APIs, and I can move fastest when using it. I've also become quite comfortable with the language and start to miss certain features (especially enums and pattern matching ) even when you ignore the usual benefits of the type system and the borrow checker.
2. Reliability and performance: In my experience, if I write something in Rust that compiles then it usually works. And if it works, then it keeps working. On top of this, it performs well and has no trouble handling high workloads.
3. Maintainability: Rust's strong and expressive type system (along with its lack of null types and the way it forces you to handle errors etc) makes it quite easy to refactor parts of the codebase, or to add new features, without worrying too much about breaking anything else.
4. Cost: Even fairly large and complex Rust programs I've written can usually run with the lowest memory/CPU tiers in serverless contexts, which reduces costs.
I used the actix-web framework to build the actual backend server. Like many backend frameworks, actix-web allows you to define your own middleware handlers, which are perfect for handling authentication of incoming requests.
Wrapping the Pangea API
Before implementing any of the core functionality associated with authentication (sign-ups, middleware authentication handlers, etc) I needed to wrap the Pangea API so it can be integrated with the rest of the system in an extendable and type-safe way.
Responses from all of Pangea's services follow this structure:
{
"request_id": "<request_id>",
"request_time": "<ISO 8601 timestamp>",
"response_time": "<ISO 8601 timestamp>",
"status": "<status>",
"summary": "<summary>",
"result": {
<result.data>
}
}
Representing this in Rust is pretty simple (we were using MongoDB, which is why the timestamps de-serialize to MongoDB's DateTime type):
#[derive(Debug, Clone, Deserialize)]
pub struct PangeaResponse<T> {
pub request_id: String,
#[serde(with = "bson_datetime_as_rfc3339_string")]
pub request_time: DateTime,
#[serde(with = "bson_datetime_as_rfc3339_string")]
pub request_time: DateTime,
pub response_time: DateTime,
pub status: ResponseStatus,
pub result: T,
}
// 'DeserializeFromStr' is a convenience macro from the 'serde_with' crate
#[derive(Debug, Clone, DeserializeFromStr, PartialEq)]
pub enum ResponseStatus {
Success,
Asynchronous,
UserExsists,
Error(String),
Other(String),
}
impl FromStr for ResponseStatus {
type Err = String;
fn from_str(s: &str) -> std::result::Result<Self, Self::Err> {
match s {
"Success" => Ok(Self::Success),
"Accepted" => Ok(Self::Asynchronous),
"UserExists" => Ok(Self::UserExists),
s if s.contains("Error") => Ok(Self::Error(s.to_string())),
s => Ok(Self::Other(s.to_string()))
}
}
}
Because the result field is generic, you can put any possible result types from Pangea's API in there. In my case, I only had to worry about a few result types from the AuthN service, along with the error type. So, for example, implementing the error response looks like this, because Pangea responds with a list of errors in case of an unsuccessful response:
#[derive (Debug, Clone, Deserialize)] #[serde (untagged)]
pub enum PangeaApiErrors {
Errors { errors: Vec<PangeaApiError> },
Null,
}
impl PangeaApiErrors {
pub fn errors(&self) -> Vec<PangeaApiError> {
match self {
PangeaApiErrors::Errors { errors } => errors.clone(),
PangeaApiErrors::Null => vec! [],
}
}
}
/// The error object returned within an unsuccessful response.
#[derive (Debug, Clone, Deserialize)]
pub struct PangeaApiError {
pub code: String,
pub detail: String,
pub source: String,
}
impl Display for PangeaApiError {
fn fmt(&self, f: &mut std::fmt::Formatter<'__>) std::fmt::Result {
write! (f, "{self:#?}")
}
}
And then, for convenience, we can create a type alias for PangeaResponse<PangeaApiErrors>
pub type PangeaErrorResponse = PangeaResponse<PangeaApiErrors>;
Now, onto the requests. Every request to the Pangea API, whether it's to AuthN or another service, has three main components: the path, the subdomain, and the request body. All Pangea endpoints accept POST requests so there's no need to worry about the method.
In Rust, we can create a trait for this.
pub trait PangeaRequest: Debug {
fn path(&self) -> &str;
fn subdomain(&self) -> &str;
fn body(&self) -> serde_json::Value;
}
For each endpoint, you could create a separate struct, but I felt like it made more sense to use enums to group request types from each Pangea service together instead. In this case, I only needed to use AuthN so I only needed one enum, but if it needs to be extended at any point in the future I'd just need to add a new enum (I've omitted some variants for the sake of brevity):
NOTE:
SecretStringis just a type alias forSecret<String>from the secrecy crate, which helps prevent accidentally leaking sensitive information in logs/traces etc.
#[serde(untagged)]flattens the enum when it's being serialized/de-serialized, so in this case theEmailOrUserIdenum will serialize either to either an "user_id" field when serialized to a JSON request body, which is useful for some of the Pangea endpoints that expect one of those field but not both
#[derive(Debug)]
pub enum AuthnRequest {
CreateUserV2 {
email: String,
first_name: Option<String>,
last_name: Option<String>,
},
DeleteUserV2 {
email_or_id: EmailOrUserId,
},
ListSessionsV2 {
token: SecretString,
},
}
#[derive(Debug, Clone, Serialize, Deserialize, ToSchema)]
#[serde(untagged)]
pub enum EmailOrUserId {
Email { email: String },
UserId { user_id: String },
}
It would also make sense to have named structs, defined elsewhere, nested within the enums. This is probably what I'd do if I was making a crate for others to use, but for a quick and dirty API wrapper that'll only use a few endpoints I think using enum struct variants is fine.
Then we implement our PangeaRequest trait for AuthnRequest
impl PangeaRequest for AuthnRequest {
fn path(&self) -> &str {
// Enum::Variant { . . } means we don't care about the inner fields
match self {
// ...
AuthnRequest::CreateUserV2 { .. } => "v2/user/create",
AuthnRequest::ListSessionsV2 { .. } => "/v2/client/session/list",
// ...
}
}
fn subdomain(&self) -> &str {
"authn"
}
fn body(&self) -> serde_json::Value {
match self {
AuthnRequest::CreateUserV2 {
email,
first_name,
last_name,
} => json! ({
"email": email,
// First and last name aren't important for our usecase but Pangea expects them anyway
"profile": {
"first_name": first_name.as_ref().unwrap_or(&"".to_string()),
"last_name": last_name.as_ref().unwrap_or(&"".to_string()),
},
}),
AuthnRequest::ListSessionsV2 { token } => json! ({
"token": token.expose_secret(),
}),
// ...
}
}
}
For a more general wrapper intended for use in other projects, it would be more sensible to modify the request types a bit and to implement the body() method to simply call serde::to_value() on &self.
Now we have types for the requests and responses, we just need to send those requests and handle the responses appropriately.
#[derive(Clone)]
pub struct PangeaApi {
client: reqwest::Client,
api_key: SecretString,
domain: String,
}
impl Pangea Api {
pub fn new(client: reqwest::Client) -> Self {
Self {
client,
api_key: SETTINGS.pangea.api_key.clone(),
domain: SETTINGS.pangea.domain.clone(),
}
}
pub async fn user_id_from_session_token(
&self,
active_token: &SecretString,
) -> Result<String, PangeaError> {
// ...
}
async fn send_request<'de, T: DeserializeOwned + Debug>(
&self,
pangea_request: impl Pangea Request + Debug,
) -> Result<Pangea Response<T>, PangeaError> {
// Calls self.post() and handles the response, there's a lot of application
// specific code here related to parsing errors and logging stuff,
// not really too relevant to the overall idea
}
// Sends the "raw" POST request to Pangea
async fn post(
&self,
subdomain: &str,
path: &str,
mut body: serde_json::Value,
) -> Result<reqwest::Response, PangeaError> {
let url = format! ("https://{}.{}{}", subdomain, self.domain, path);
let response = self
.client
.post(&url)
.header(
"Authorization",
format! ("Bearer {}", self.api_key.expose_secret()),
)
.json(&body)
.send()
.await
.map_err (PangeaError::from)?;
Ok (response)
}
}
I've omitted a few other methods because I'm just going to focus on the actual authentication step, which uses the user_id_from_session_token method.
The only parameter it needs is the user token sent from the frontend as a cookie in the request, and it retrieves the associated user ID from Pangea by using the /v2/client/session/list endpoint. This was the only thing I really found confusing about the API, because it's a "client" endpoint so I assumed that the /v2/session/list endpoint would be more appropriate to use from the backend, but that endpoint requires you to already have the user_id and all we're getting from the frontend is the client token.
pub async fn user_id_from_session_token(
&self,
active_token: &SecretString,
) -> Result<String, PangeaError> {
let pangea_response: ListSessionResponse = self
.send_request (AuthnRequest::ListSessionsV2 {
token: active_token.clone(),
})
.await?;
let sessions = pangea_response.result.sessions;
ensure! ( ! sessions.is_empty(), PangeaError::ExpiredToken);
let user_ids: HashSet<String> = sessions.into_iter()
.map(item item. identity)
.collect();
// There should only be one `user_id` associated with a token
ensure! (user_ids.len() 1, PangeaError::Internal);
// Unwrap is fine because we already checked the length
Ok (user_ids.into_iter().next().unwrap())
}
If you're actually using sessions, you'll of course want to do something with them. In this case, we're not using Pangea for session management, we just care about making sure the user is signed in by verifying that the request has a valid token in the cookie, and we also want to get the user_id so we can fetch the user's info from our own database.
Middleware
Now we have a wrapper around the API, we can use it in a middleware to authenticate requests to any endpoints requiring authentication. The actix_web_lab crate provides a function which simplifies writing a middleware handler. In our case the function signature looks like this:
pub async fn user_auth(
db_controller: web::Data<DbController>,
pangea_api: web::Data<PangeaApi>,
mut req: ServiceRequest,
next: Next<impl MessageBody>,
) -> actix_web::Result<ServiceResponse<impl MessageBody>>
NOTE: Actix-Web Related Stuff
The first two parameters are actix-web
extractors, they basically ensure the database controller and the Pangea API client are passed into the handler from the app's internal data.The next two parameters are required for any middleware function.
reqis the request, and contains the body, headers, etc.
nextis essentially the next middleware handler that will be called after this one (if it doesn't reject the request)
For simple authentication, all this function needs to do is extract the relevant cookie from the request and then parse the Pangea user token from the cookie. Once you have the user token, you can call the pangea_api.user_id_from_session_token() method and if it's a valid token you'll have the user_id which you can then use to check your database for the relevant permissions. In our case, we use it to check that the user actually owns the business they're attempting to manage in the dashboard.
In actix-web, you can wrap any endpoints that require authentication with the middleware function. It makes sense to group these endpoints into a shared scope to avoid accidentally adding endpoints in the future without wrapping them with the middleware.
cfg.service(
web::scope("/dashboard")
.wrap(from_fn(user_auth))
.service(endpoints::dashboard::get_info)
.service(endpoints::dashboard::edit_info)
// ... etc
);
Different frameworks will handle the implementation of this in a slightly different way but the general idea is the same: create a middleware that authenticates the request and ensure all requests requiring authentication go through it.
Overall Experience
My overall experience with AuthN was pretty smooth. Adding users was even easier than the authentication step, all I had to implement was an admin endpoint that takes the user's email and the IDs of the business(es) they own and it calls the Pangea v2/user/create endpoint to create the user before adding the returned user_id to the database.
Once this is done, the user is prompted to verify their email with a magic link when first signing in before being asked to set a password. So the sign-up flow is largely handled on Pangea's end, and hosting the login page on our own subdomain was straightforward.
I didn't have a lot of involvement with the business dashboard's frontend, but we were using React on the frontend and Pangea has a React library for integrating with AuthN. This is actually one of the other reasons I chose Pangea, because I didn't want to give the front-end dev a bunch of extra work to do.
A bit of coordination was required between myself and the frontend dev, because I initially thought I had to use the /v2/session/list endpoint instead of /v2/client/session/list, and this meant we were using the token_id (prefix: pmt_ ) rather than the token_value (prefix: ptu_ ) which wasn't being stored as a cookie. Once I realised I was supposed to use the /v2/client/session/list endpoint, and therefore the ptu_ token, everything was much simpler on the frontend and he was able to get back to focusing on actually implementing the core functionality.
Using AuthN meant that in the grand scheme of things I spent very little time implementing authentication, and was able to instead spend the majority of my time on the core business logic.
If you happen to need a backend software engineer, you can email the author at info@0xf00d.devfor any inquiries.


