Pangea is the first Security Platform as a Service (SPaaS) providing a comprehensive set of services for a broad set of security use cases such as audit logging, PII redaction, embargo, file intelligence, IP intelligence, URL intelligence, domain intelligence, secrets and key management and many more. By the end of 2023 we will have launched over 24 services, including authentication, authorization, secure object storage, file scan and detonation, and breach intelligence.
These services are all delivered through an API model, designed to be embedded directly into cloud applications, and to be called during application runtime, either through our SDKs that are available in multiple languages, or directly via REST. Each service serves very distinct use cases and hence has very different response characteristics. Most services respond synchronously while services like file scan will often have an asynchronous response, depending on the file size and other parameters. And hence these services have distinct scale and performance characteristics. With these distinct use cases, the platform has to be architected to meet 3 key requirements:
Serve all API calls and also be able to handle varying patterns of workloads across all use cases i.e. short and long bursts/spikes of requests
Have best performance i.e.have least response times at all times
Be cost effective
The backend has to be elastic to add (or release) capacity as the workload patterns fluctuate while maintaining ideal performance i.e. response times. We are constantly testing each service and its APIs for its scale and performance characteristics to right-size the deployment and to ensure that they are pre-provisioned with the right compute and memory capacity. In addition, each service deployment has preset kubernetes replicas to handle “normal workloads” for respective services. Pangea also leverages Kubernetes capabilities like HPA (Horizontal Pod Autoscaling) to ensure that the services can add new capacity to handle fluctuating workloads.
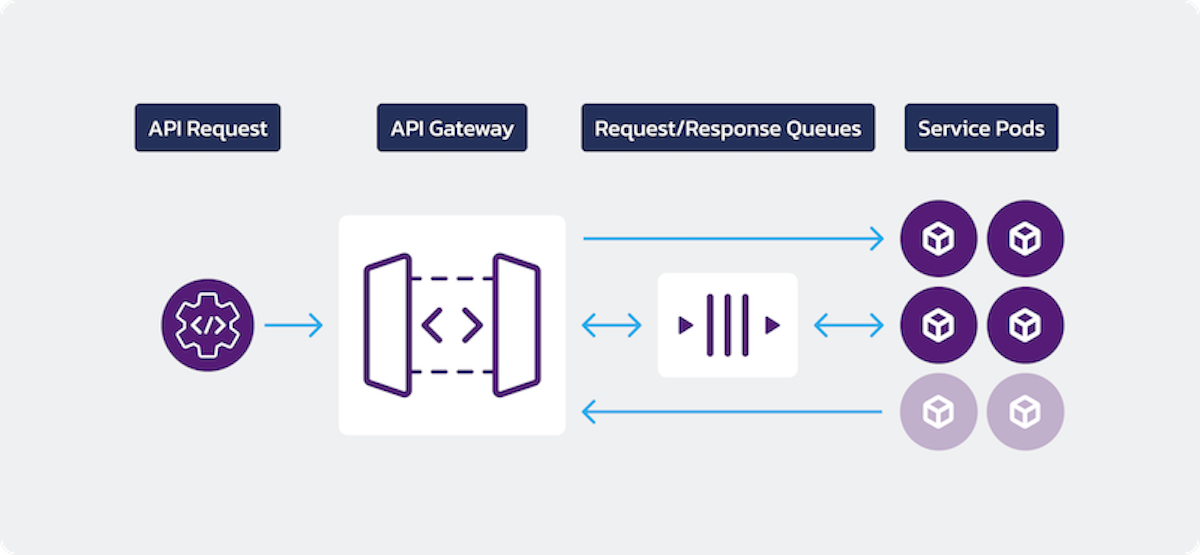
In normal conditions, the API requests are received by the API gateway and directly forwarded to the service which returns the results to the API gateway, and the user receives the results fast and synchronously. However as the load increases beyond a certain threshold, the platform scales to maintain expected performance. As load increases, performance metrics trigger HPA. We are extending the platform to introduce very service specific metrics that can trigger HPA above and beyond basic metrics like CPU and Memory utilization. As new pods are being added (via HPA triggers) to the deployment, the existing pods may not be able to handle/accept new requests, depending on how fast the load increases. And there are many other edge cases and scenarios, like continuous deployments, resource unavailability due to ongoing workloads, etc. that can cause issues where a service may be unable to accept requests in a timely fashion.
“Retries” is a very common strategy to increase the probability of fulfilling the request but may not be a suitable strategy in all the cases. Retries can include timeouts, which means that the request connection is still held on to. Each open request connection consumes resources. This can gradually result in exhausting resources and thus reduces the ability to handle/accept new requests. Retrying the request on a service that is already at capacity can further deteriorate and stress the service. There are “exponential backoff” strategies that can be used with retries but that does not help with resources being consumed with every client connection that is still open.
The Pangea platform has been architected to address these issues by creatively and opportunistically leveraging queues as a secondary (failover) channel for accepting requests and responding even when the service pods are otherwise temporarily unavailable. This strategy helps release resources as fast as possible. This allows ongoing requests to be serviced faster.
In most cases, the API is synchronously serviced with the best response times. However, if the pod is unavailable or unable to accept new requests in time or when the service response times have degraded significantly, the API gateway sends the new request to the service over the queue. Once a request is pushed over the queue, for a certain number of requests or time, subsequent requests are not attempted synchronously thus allowing service to complete ongoing requests and relieve resources fast. Meanwhile HPA kicks in and works on adding more capacity (pods) to the service. Now a higher volume of synchronous requests can be processed. Pangea services are designed to accept requests directly from API gateway and can also get(fetch) the requests from the queue. Thus API requests are always serviced and the worst case scenario is that the API response time (performance) is degraded temporarily while new capacity is being added to the service. And as soon as more pods become available and more capacity is available, synchronous requests resume working and performance is restored; hence response time degradation self corrects as new capacity is added to the service. While requests are temporarily asynchronous, the API gateway can still hold on to the client connection and return the responses synchronously (in many cases) as soon as the service responds to the request that it fetched from the queue. Hence, to the client, request is served synchronously even though internally the request was serviced asynchronously.
This approach is only relevant to a subset of use cases and not a generic solution for all scenarios. But, where applicable, it does allow us to maintain a fine balance between three areas i.e. cost, elasticity and performance. The service abstraction layer that has been implemented hides away all of this complexity (request response traversal, direct or over the queue) for service authors and allows them to focus on the core service logic i.e. request handlers.
I would love to hear your thoughts about this approach or similar alternative approaches you have taken that you are willing to share. All in the spirit of “open architecture”, continued from my previous blog post.


