
Intro: Analogies
Network security back in the 1990’s through the mid-2010’s was a very exciting time where user connectivity rapidly evolved, creating tons of vulnerabilities and exploit techniques that all happened over the network and internet. This yielded the creation of numerous network security tools, open source projects, and companies building products for that landscape. Personally, for me, the entire scene was fun and fascinating.
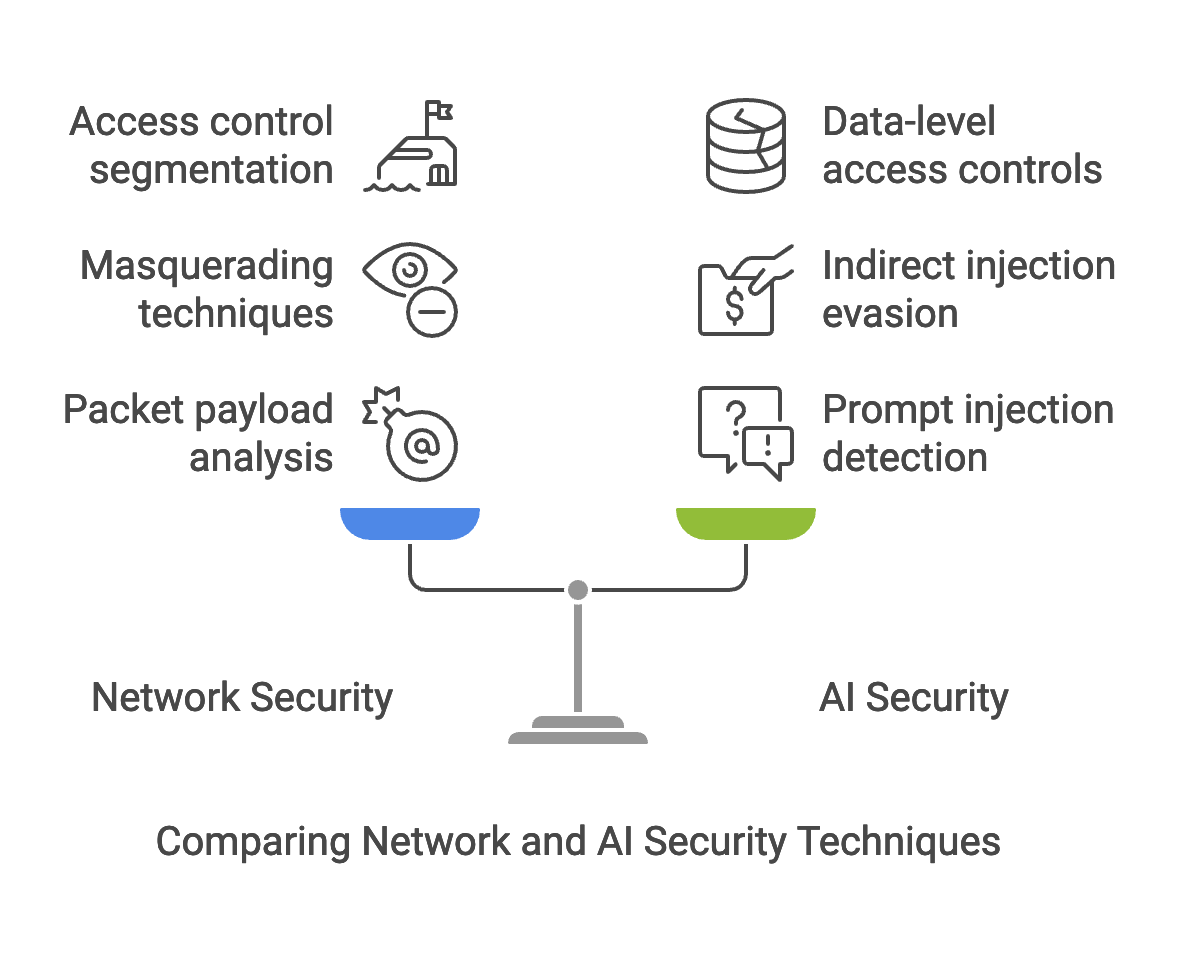
There’s a sense of déjà vu with what is happening right now in the AI and application environment, with the creation of totally new attack vectors and techniques (such as those documented in the OWASP Top Ten for LLMs) that bear a resemblance to network security challenges. What security techniques can be refreshed and reused from the network security days and applied to today’s threats against AI apps?
1st Analogy: Analyzing Packet Payloads Prompts for Threats
Network Security Technique: Analyze packet payloads
AI App Security Objective: Protecting the LLMs from abusive prompts
Intrusion detection and prevention systems analyze network packets and packet payloads for attempts to exploit devices or applications, typically via detection signatures applied to the data payloads of the network packets. The equivalent in AI security are attacks embedded within prompts submitted to an LLM, where the contents of the prompt are equivalent to the data payload of a network packet in this analogy.
AI prompt injection attacks aim to drive unintended behavior of LLMs to achieve consequential outcomes such as information leaks, jailbreaks, or code/binary execution against sensitive systems. The network security equivalent is an attacker targeting a corporate web server and exploiting vulnerabilities in the Apache service (or other web server daemons). In the latter case, the attacker exploits a vulnerability likely resulting in a buffer overflow where the attacker feeds the exploit executable code to open back-door access to a system or fetch sensitive data. In the modern AI landscape, an attacker builds specially-crafted prompts to force a jailbreak situation where the LLM or broader system starts making decisions (perhaps autonomously) that are outside of the original programmer’s prompt template instructions.
In AI security the equivalent to network intrusion detection is the concept of a prompt guard (or prompt guardrail), where the contents of the prompt are inspected and evaluated for prompt language signaling an attempt to manipulate the behavior of the LLM. A prompt guard is a form of a modern intrusion detection (or prevention) system to protect LLMs. At the time of this writing, there are several emerging companies experimenting and building capabilities that protect against this threat.
What’s also interesting about this AI attack vector is that it can manifest itself in several different ways that are outside of submitting a malicious instruction through a prompt or chat user interface.
2nd Analogy: Evasion
Network Security Technique: Masquerading and fragment reassembly
AI App Security Objective: Protecting the LLMs from abusive prompts
Prompt injection receives a lot of hype right now, but what I feel is more interesting is indirect prompt injection. Indirect prompt injection is a form of evasion, whereas prompt injection attempt occurs through a means other than the user entering text directly. This usually takes the form of a file object, though it can take place in other ways via image, audio, or video file potentially. These file objects can enter via RAG (retrieval-augmented generation) architectures where data is merged with a user prompt for added context in order to deliver a more informed response or enriched user experience. This can similarly be done though through other architectures such as agentic frameworks, fine-tuning models, and training data.
The threat in this scenario is one where if an attacker understands the application architecture, or the data sources, or discovers any of the above through brute-force trial-and-error methods, they can embed prompt injection attacks into the file objects. The most simple example is embedding prompt injection commands into a Google document and sharing that with a user. Through the use of RAG or agentic frameworks, the user would not even need to open that document for the prompt injection attempt to occur. The AI system processes the document, as instructed, and by way of processing, it may process the prompt injection command. This is a clever way to work around controls such as prompt guards looking only at a user input prompt. This is evasion.
Another form of evasion is through splitting (or fragmenting) the prompt. For example, a fraction of the prompt injection command is submitted through the user prompt interface, while the remainder of the prompt injection command embeds in a document ingested through a RAG pipeline. The fragmented commands in isolation would evade detection of a prompt guard, but these commands may be unified deeper into the application pipeline via reassembly or merging of the prompt with fetched data context. Once that unification occurs, the full prompt injection string may be processed by the LLM where unintended outcomes are likely to occur.
These are very sophisticated forms of evasion that include techniques such as masquerading and fragmentation, all of which are observed in network security offensive techniques. Attackers could assemble extremely large payloads, deliver them to their target via deliberate packet fragmentation, and even time the delivery of each network packet to aid in evading detection. As a result, detection and prevention devices needed to augment their engines to identify these and subsequently included features such as state tracking, asset tracking, packet reassembly, and other features. Once re-assembly occurs, the full threat analysis engines could operate on the re-assembled payload.
We will need to employ similar techniques here with LLMs and prompt injection attempts. This includes piecing together the entire prompt at different points within the application architecture in order to deliver a complete view of the prompt to the prompt guard or other detection engine responsible for protecting the LLM.
This covers the payload elements to some degree, but the relationships back to classic network security techniques do not stop there. Read on to move down the OSI layer model (in the analogy) and we will cover access controls.
3rd Analogy: Classic Network Security Controls and Segmentation (Protecting Access)
Network Security Technique: L2/L3 Access Controls
AI App Security Objective: User/File Access Controls
When anyone thinks about classic network security capabilities, things like firewalls, routers, VLANs, and ACLs come to mind. Each of these delivers a form of segmentation via different techniques that are applied at different layers of the network and OSI layer model, mostly L2 through L4 (in OSI-speak). At one point in time, these were extremely cutting-edge security controls, and while their importance hasn’t been reduced, they are standard approaches that every responsible security team employs.
But these types of tools do not operate at the application or data level, they are purely for ensuring secure transmission and transport of data. The “secure” descriptor takes the form of Access Controls. In the modern AI app landscape, network-level access controls are still present however they are usually handled by the infra team and not the application developer or LLM specialist. But we still have access control problems we need to worry about, and they take the form of data or application-level access controls. Imagine this use case: A user submits a prompt, and the AI application utilizes a RAG ingestion pipeline to fetch contextual information to better respond to the prompt. In that scenario, how do we ensure that the data being fetched is sourced from a document or file for which that user (or application) has access permission? This situation is ripe for someone to accidentally or deliberately attempt to access something they shouldn’t have access to. There are other forms of this architectural vulnerability with agentic frameworks as well. In agentic frameworks, there is more autonomy of the agent and that agent has access to tools, systems, and APIs. In a worst-case scenario, a user could submit prompts that result in unauthorized access to critical systems in the enterprise.
This is where access controls at the application, data, and user layer are so important. At one point in the historical evolution of network security, it was possible to solve this type of problem through network segmentation, firewall rules, and ACLs. That’s not as relevant now in the context of AI applications. We need to apply the segmentation and access controls at the data, systems, tools, APIs, and other assets higher in the application stack.
Solving this requires a mixture of strong identity tracking and synchronized authorization rules for the various assets being accessible in real time at the core of an AI application. For example, as the contents of a Google document are fetched and broken down into vectorized chunks to store in a vector database, the permissions for that document need to be persisted with the data. At the time of user access, that user identity must also persist through the app and be checked against the permissions of vector chunks fetched during the context-gathering phase. Doing this is easier said than done, but there are developers and companies looking to solve this problem.
These first three analogies round out the typical hygiene you would expect in either network security or AI application security, covering the basics of what everyone should expect in those disciplines. Hopefully, the parallels help you understand some of the key security concepts in the context of AI applications. The next section needs no analogy - please read on.
4th Analogy: Protecting Users and Apps from Malware
Network Security Technique: Block and prevent the spread of malware
AI App Security Objective: Block and prevent the spread of malware
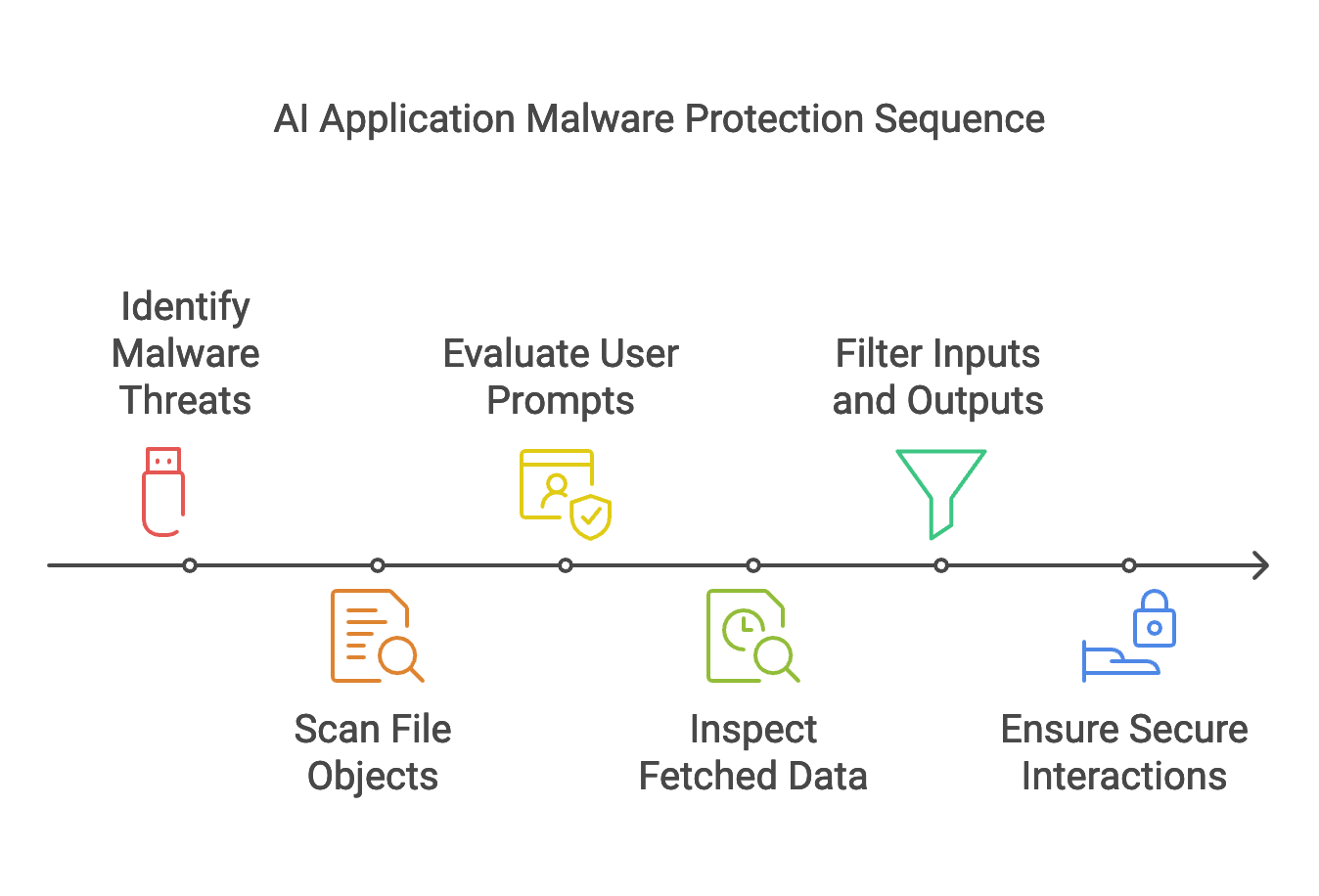
You did not misread the linkage in this section’s description. Malware is still, and will always be, a concern in any environment. In the context of AI applications, the AI threats we’ve discussed are AI-specific. Now we will address the need to ensure that our AI application is not a means to distribute malware or link users to malicious content. To do this, we do need to look into the contents of prompts being fed into the LLM, as well as data being fed into the LLM from any source (user, RAG, agents, etc). To be as secure as possible, we need to ensure the following for every transaction with a user or system:
If we’re exchanging file objects, that file object itself is not malware
Prompts from users do not contain links to malicious URLs, or domains, and do not reference malicious IP addresses
Data fetched for context do not contain links to malicious URLs, or domains, and do not reference malicious IP addresses
Incoming prompts, outgoing responses, and interactions with external systems need to be evaluated for these types of threats or threat indicators. This same type of scrutiny can be applied to sensitive corporate information or personally identifiable information as well. Your AI app should avoid handling or processing any of the above. To achieve this, the application needs to have the means to scan and filter inputs and outputs to protect users and assets, and ensure the AI app is not a vehicle for malware distribution.
Closing
There’s a lot to take into consideration, but for those that lived this in the past, there is a lot to draw from and many parallels between the two worlds. When you think about this at the 100,000 foot view, they are very similar to one another (or perhaps I just can’t let go of my passion for network security). The differences lie in the fact that the networking layers are now replaced with APIs and inter-process calls, and the asset we’re focusing on protecting is the LLM, in addition to corporate data and users.
The new interception point is via API - these protection and mitigation strategies need to be stitched into the application flow via APIs. To complete the analogy, an intrusion detection or prevention system is stitched into the broader environment via networking cables and maybe some crafting VLAN segmentation or routing. But now we need to use APIs to inject these protective mechanisms to evaluate user prompts, incoming data, autonomous agent activity, and responses back to users. Identifying the right points in the application flow to intersect and get a complete view of the requests is important, much like selecting the right location for a network firewall or packet analysis tool.
The rules or threats we look for may differ depending on where in the application stack we’re evaluating the subject material. Similarly, a network security engineer will apply a particular set of signatures for intrusion prevention on the ingress of their network, and a different set of signatures for the egress of their network.
Enough hanging out in the 2000’s. Let’s go secure some modern AI applications!


