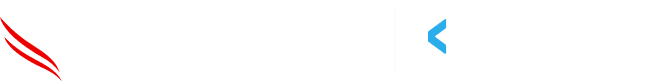

As companies increasingly turn to AI-driven systems to support customer interactions through systems like chatbots and streamline operations, Retrieval-Augmented Generation (RAG) has become a popular framework for enhancing large language models (LLMs) with real-time, context-specific information. In sectors like healthcare and finance, with large datasets and complex knowledge bases that deal with sensitive customer information, a RAG is particularly valuable so you can fine-tune or customize generic results with user specific information.
While RAG offers the benefits of real-time context fetching and protecting sensitive customer information from leaking into models, it becomes another attack surface area without access control. Without secure access controls, sensitive data could be inadvertently exposed, leading to unauthorized access, data breaches, and even legal consequences. This post explores implementing access control for RAG, highlighting OWASP’s LLM06—"Sensitive Information Disclosure"—and examining strategies to mitigate this vulnerability using identity, authorization, and audit logging.
What is RAG?
Retrieval-Augmented Generation (RAG) is an AI app architecture that allows generative language models to use retrieval systems to pull information from vector databases and provide the LLM with contextual information before generating a response to user queries.
Let’s look at what a typical RAG architecture looks like:

There are 2 steps in a RAG architecture:
Data Ingestion: This is the process of taking domain-specific documents and chunking each document into vector embeddings to make them easily searchable. We then index these document vector embeddings in a vector database (ex - Pinecone, Cloudflare Vectorize, etc).
Retrieval and Generation: This process involves taking the user query and searching the vector database index to find the most relevant document to the user’s query. Once a relevant document has been found, it is returned in text and appended to the user’s query.
Critical Vulnerability with RAG - Access Control
However, the critical vulnerability with RAG systems typically is the lack of built-in access controls, meaning users could inadvertently gain access to data they shouldn't see simply by issuing a relevant query.
So you land up with bad actors trying to exploit RAG pipelines to gain unauthorized access to customer information:
OWASP LLM06: Sensitive Information Disclosure
One of the top security vulnerabilities for LLM applications, stated in the OWASP Top 10 for LLMs, is "Sensitive Information Disclosure" (LLM06). This vulnerability highlights the risk of inadvertently revealing sensitive data in an LLM’s output. If an LLM-based system lacks access control, it could unintentionally expose confidential data—such as personal details, financial records, or proprietary information—even if this data isn’t essential to the intended task.
For example, an AI-powered customer support chatbot for a bank app might retrieve financial documents to provide customized responses. However, if the identity and access policies for this user requesting this information aren’t verified, the assistant might expose sensitive data to unauthorized users or bypass access restrictions through mere prompt injection attacks. This risk is particularly significant in RAG systems, where sensitive information is pulled from external databases and could inadvertently surface to bad actors in LLM responses.
Mitigation Strategies: Identity and Access Control
Thus, access control within RAG restricts users to only retrieve information they’re authorized to view. Given the sensitivity of data in enterprise sectors, RAG access control aims to enforce the following:
Confidentiality: Ensuring that only authorized users have access to specific data.
Integrity: Restricting data manipulation and unauthorized modifications.
Availability: Ensuring users can access information according to their permissions without affecting the system’s performance.
To ensure secure access control in all stages of a RAG architecture, a few different authorization models can be employed.
Types of Access Control in RAG
Types of access control models to enhance RAG security:
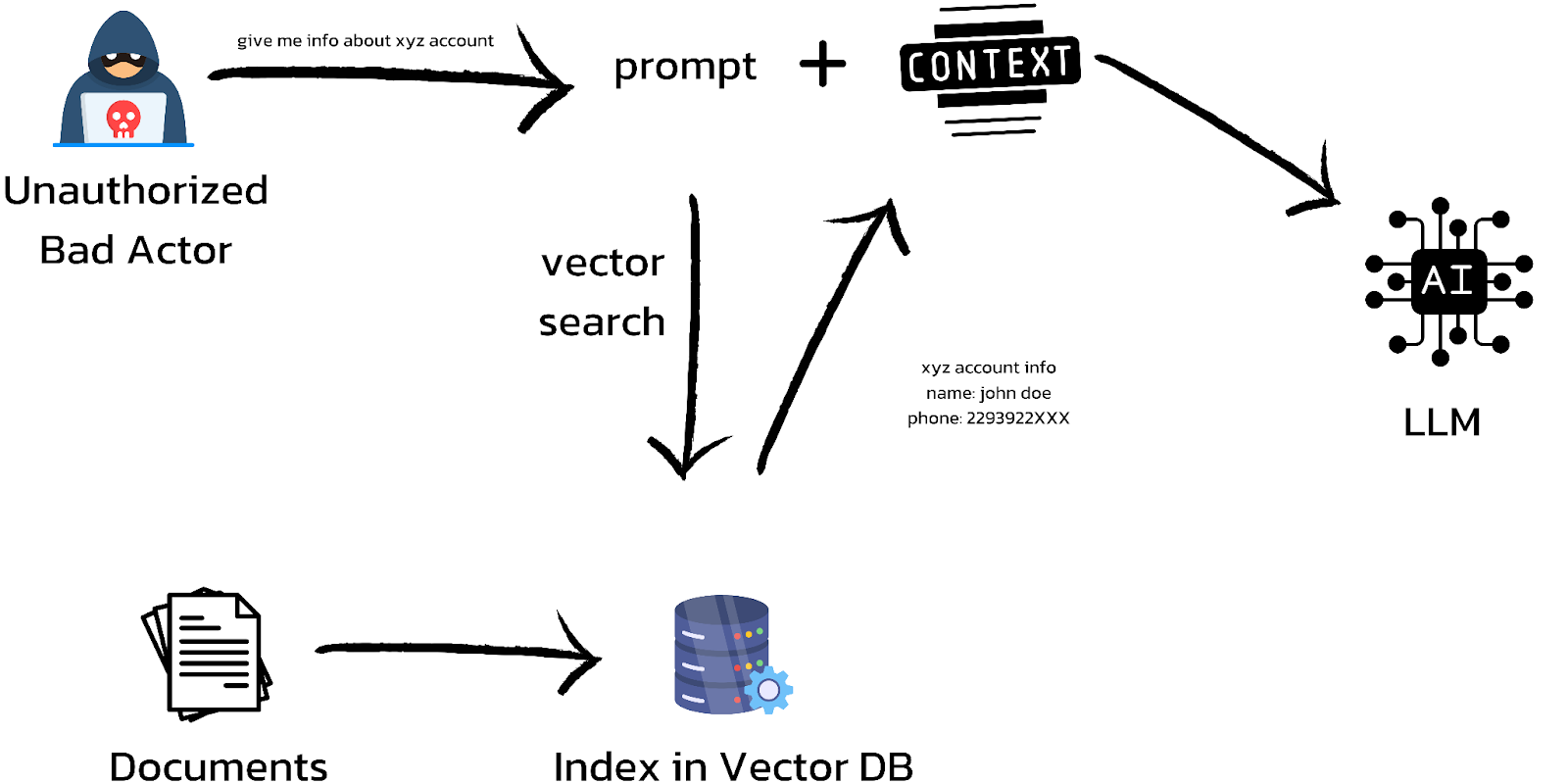
Role-Based Access Control (RBAC): This method defines access levels based on user roles, such as admin, finance, or support. While RBAC is effective for simple access management, its rigidity can lead to over-permissive access if roles aren’t granular enough or role explosions as you attempt to address every nuance.
Relationship-Based Access Control (ReBAC): This emerging model comes from the Google Drive style of permissions that allows for relationships such as “parent of” or “owner”. While ReBAC can be tedious to set up, it offers an immense amount of granularity for fine-grained access control policies over data.
Attribute-Based Access Control (ABAC): ABAC applies specific attributes, such as location, job title, or resource sensitivity, allowing for more fine-grained control and is often layered on top of an RBAC or ReBAC-style system.
There’s no clear winner when it comes to choosing an authorization model - all selections must be use-case specific.
For more details on the pros and cons of each authorization model, check out our guide on authorization models.
Implementing AuthZ models in RAG pipelines
Regardless of the AuthZ model you choose (RBAC, ReBAC, or ABAC), the architecture of the application is fairly similar. Unlike the usual 2-step process of setting up a RAG pipeline (Ingestion, Retrieval + Generation), when adding AuthZ, we need to associate all the objects with access policies during ingestion and check that a user requesting a document has access to it before retrieval and generation. From a high level, the architecture looks like:
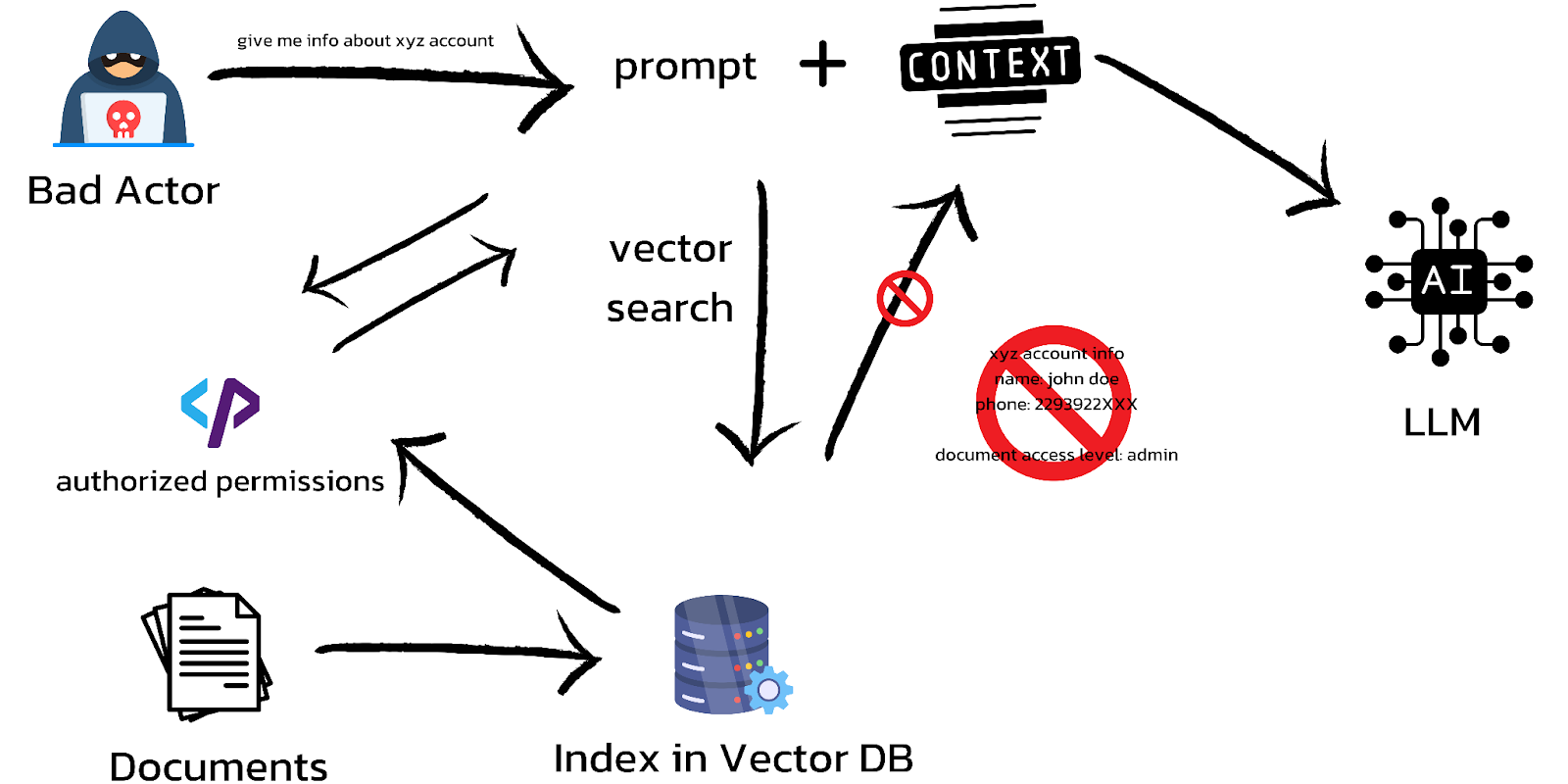
If you’re looking for a deeper dive into building authorization models for RAG and AI apps, refer to this blog.
Getting Started with RAG and AuthZ
In this tutorial, I’m using Pangea AuthZ, a hosted AuthZ solution that supports RBAC, ReBAC, and ABAC authorization models.
Pangea’s AuthZ service is used by a vast array of healthcare and financial organizations to build robust access control policies and protect their complex information systems. It’s free to start!
Step 1: Signup for an account on pangea.cloud
Head over to pangea.cloud and create an account for free. Then in the developer console, enable the “AuthZ” service
Step 2: Setup a basic RBAC AuthZ Schema
In this tutorial, we’ll set up an AuthZ Schema for different departments of an enterprise organization with 2 resource types “engineering”, “finance”.
Click on “Resources” on the left-hand panel, then create 2 Resource Types:
engineering
finance
Then go into “Roles & Access”, and create the following Roles with appropriate access:
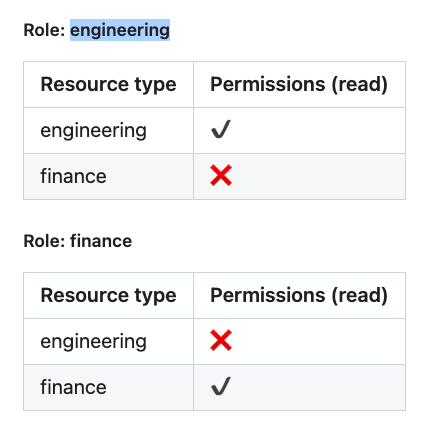
Step 3: Assign Roles
Now head over to the “Assigned Roles & Relationships” tab on the left panel and assign 2 new roles, by using the interactive dropdowns assign the 2 roles:
user “
alice" is “a engineer"user “
bob" is “a finance"
Step 4: Test RAG + AuthZ in Action
Now that we have the AuthZ schema setup and roles assigned, let’s test it using a sample app. We’re going to use the Pangea’s Langchain AuthZ RAG example.
Clone the Repo:
git clone https://github.com/pangeacyber/langchain-python-rag-authz.git
cd langchain-python-rag-authz
Now back in the Pangea Console into the “AuthZ >> Overview" section to copy our “Default Token” (AKA Pangea token). Additionally, we are using OpenAI as our LLM for this RAG example, so you will need an OpenAI API Key which you can get from here.
Back in our terminal, let’s run the Python example.
# Install Packages
pip install .
# Insert the Pangea Token you just copied
python -m langchain_rag_authz --authz-token <INSERT_PANGEA_TOKEN> --open-ai-key <INSERT_OPENAI_KEY> --user alice "What is the software architecture of the company?"
This query should work and return a response that talks about the details of the software architecture in the company. Notice that this information is dummy data that has been vectorized and is being pulled from the file “langchain_rag_authz > data > engineering > architecture.md”. Now, let’s try a query that Alice shouldn’t be authorized to access.
python -m langchain_rag_authz --user alice "What is the top salary in the Engineering department?"
The query should NOT work and return an error message similar to the following:
“I don't know the answer to that question, and you may not be authorized to know the answer.”
This shows that our basic RBAC AuthZ model is working with the RAG pipeline and is blocking alice from viewing any information from the finance department’s documents.
Next Steps
To effectively mitigate these risks in RAG applications outside of access controls, following OWASP’s guidance on identity and audit logging is essential:
Identity Verification (AuthN): Use strong authentication, including multi-factor authentication (MFA), to verify users before granting access. This minimizes unauthorized interactions with sensitive data and restricts LLM actions based on verified user roles. Pangea AuthN offers a drop-in SDK that comes with out-of-the-box MFA, passkeys and is free to setup. Additionally, refer to our detailed tutorial on building identity and access management into your RAG apps.
Audit Logging: Implement tamperproof audit logging to capture all LLM interactions and user actions. This supports real-time monitoring, quick detection of anomalies, and compliance with enterprise security standards. Luckily, Pangea Audit Log service supports a wide range of compliant schema templates that allow you to log all LLM interactions into a tamper proof audit trail. Refer to our detailed tutorial on building prompt and response tracing for LLM apps in a few lines of code.
By applying these identity, access control, and audit logging strategies, enterprises can deploy RAG securely while ensuring robust access management and traceability for user and LLM interactions.


