Edge Overview
The Edge deployment model gives you control over sensitive data while benefiting from the convenience of Pangea’s hosted control plane.
Edge bridges the gap between fully hosted Pangea SaaS and Private Cloud deployments, supporting AWS, Azure, and GCP. With Edge, you run specific Pangea services locally, while managing them through the Pangea cloud console.
Data is processed entirely within your environment, ensuring sensitive information never leaves your infrastructure. At the same time, Pangea’s cloud platform handles service configuration, updates, and monitoring - so you don’t have to manage the full platform yourself.
Edge currently supports the following services:
- Redact
- AI Guard
Key considerations
- Data locality - Sensitive data is processed within your cloud environment, helping you meet data residency and control requirements.
- Pangea-hosted control plane - Manages configuration and collects usage metrics. You gain compliance and data sovereignty benefits without the burden of managing the full software stack.
- Technical expertise - Requires moderate infrastructure knowledge. Your team must deploy and manage Pangea services using container images, which is manageable for teams familiar with containerization and cloud platforms.
- Best for - Teams that need localized processing for compliance or latency reasons and are comfortable with configurations and metrics being handled outside their cloud boundary.
How it works
Overview
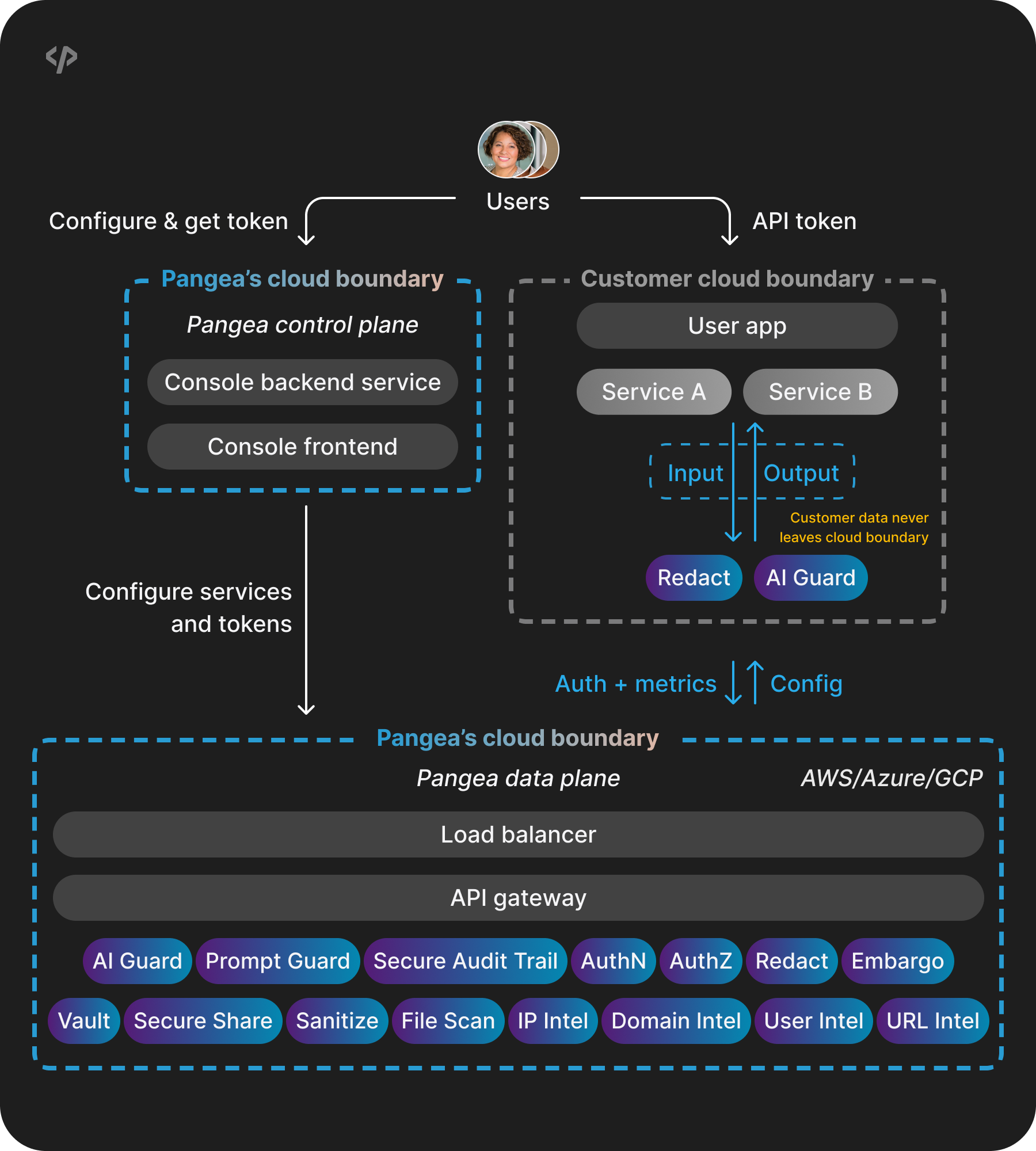
Core components
The Edge architecture includes two main parts:
-
Customer cloud components
- Services you run within your cloud environment.
- Specific Pangea services (such as AI Guard or Redact) are deployed as container images in your environment.
- These services process sensitive data locally, ensuring that raw data never leaves your control.
-
Pangea cloud components
- Control plane - Manages service configuration and token management.
- Data plane - Provides core Pangea services through the SaaS infrastructure.
- Metrics collection - Collects operational metrics for monitoring and insights.
Operational flow
Your data follows these steps:
-
Your applications interact with Pangea services deployed in your environment, sending requests for data processing.
-
These services process all data locally within your infrastructure - raw data never leaves your environment.
note:By default, requests to the AI Guard APIs and their processing results are saved in the service's
Activity Log . You can query, enable, or disable the Activity Log in your Pangea User Console .To prevent audit logs from being sent to Pangea-hosted SaaS, you can configure your deployment to redirect logs to standard output.
For details on customizing your Pangea Edge deployments, see the corresponding guides:
-
Processed results are returned directly to your applications through your internal network.
-
The services maintain a connection to Pangea's control plane to:
- Send authentication status and usage metrics back to Pangea.
- Receive configuration updates from Pangea.
Deployment options
Edge supports two deployment approaches:
Single container deployment, which provides a straightforward path to implementing Edge. This approach works well for:
- Development environments.
- Proof-of-concept implementations.
- Scenarios with moderate processing requirements.
Kubernetes deployment, which provides additional operational capabilities for production workloads:
- Container orchestration for service management.
- Built-in scaling capabilities.
- High availability options.
- Standard Kubernetes monitoring and logging.
Next steps
Now that you understand Edge architecture, you're ready to start implementation. Use the following guides to set up, test, and deploy Pangea Edge services on your preferred platform:
- Enable and configure Pangea Edge services
- Test and evaluate Pangea Edge services with Docker
- Deploy Pangea Edge services on AWS
- Deploy Pangea Edge services on Azure
- Deploy Pangea Edge services on GCP
Was this article helpful?